AI Governance · Human Review · Audit Trail
Automate customer support with control built in.
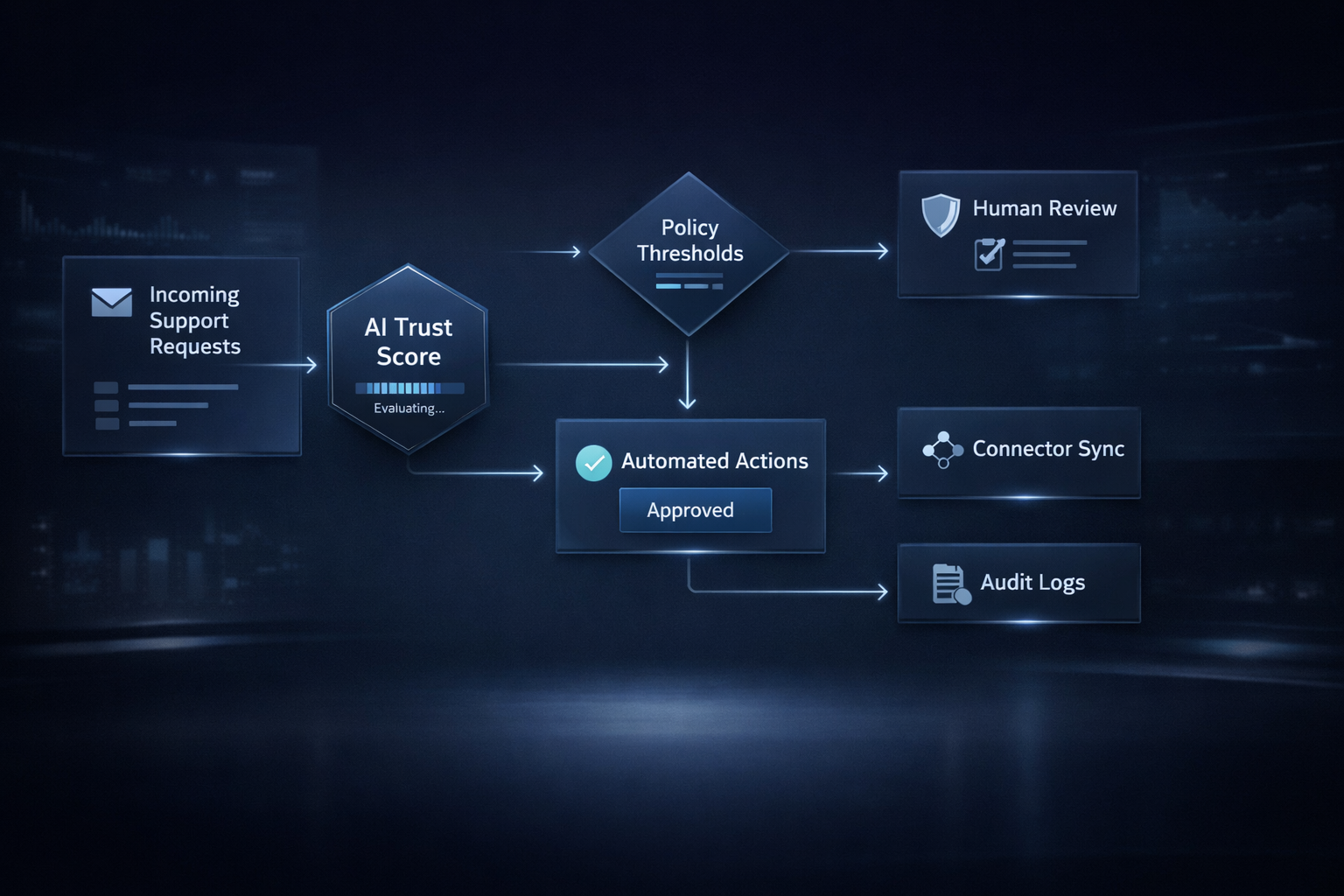
FortiAgent resolves customer support queries using grounded knowledge and live connector data. FortiVault governs every decision with an AI Trust Score and automation gating policy.
Reduced support workload, improved response consistency, safer automation expansion, and full oversight of every AI decision.
Built for enterprises that need AI customer support they can measure, audit, and safely scale.
14-day free trial · No credit card required · 1 business day setup